Martin Šmíd, UTIA AV ČR
Dne 24.2. jsem byl požádán, abych jako podklad pro jednání orgánu NERV zpracoval prognózu dalšího vývoje klíčových ukazatelů epidemie pro různé varianty opatření, o kterých se tou dobou jednalo.
Výsledek, odeslaný na jednání, byl následující.

Začátkem března jsem od Petra Holuba, redaktora Zpráv Seznam, obdržel několik dotazů týkajících se modelu, použitého při tvorbě předpovědí. Tyto dotazy z velké částí pocházely od členů České statistické společnosti, které Holub požádal o posouzení modelu. Dne 11. března pak vyšel na toto téma článek Hamáčkova předpověď o 20 tisících nakažených nevyšla. Proč?
Na článku je třeba ocenit, že se diskusi o modelování epidemie snaží alespoň částečně posunout na věcnou rovinu, a že k posouzení modelu vyzval odborníky (jakkoliv se jedná o kolegy, kteří dlouhodobě zpochybňují matematické modelování biologických procesů už ze samotného principu – zajímavý je třeba jejich spor s Janem Kulveitem zde). Bohužel, Petr Holub se ve svém článku nevyhnul několika nepravdám a manipulativním tvrzením. Dovolím si je pro začátek shrnout.


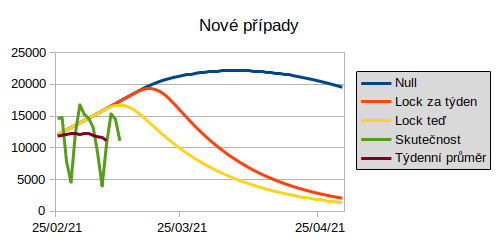
Vraťme se však k tomu důležitějšímu – diskusi o modelu samotném. Vzhledem k tomu, že jde o model stochastický (zahrnující náhodu), nelze předpokládat, že poskytne přesnou předpověď. Čáry v grafech znázorňují jen jakousi střední předpověď. Tyto bodové předpovědi by správně měly být doplněny mezemi nejistoty (konfidenčními pásy). Tyto hodnoty náš model počítá, v prezentaci pro NERV bohužel nejsou uvedeny, a to z toho důvodu, že jsem na výpočet měl dvě hodiny, přičemž odhad šířky konfidenčních pásů by si vyžádal hodin několik (disperzní parametry se v tehdejší verzi modelu odhadovaly zvlášť).
O selhání stochastického modelu se dá mluvit až v případě, kdy se předpovědi systematicky ocitají mimo tyto pásy, což tady bohužel nastalo u počtu nových případů.
Důvod, proč se tak stalo, není ani tak přeučenost modelu (má sice 37 parametrů, ale také 300 x 19 = 5700 pozorování), jako spíše nejistota o nakažlivosti nové varianty a míry její prevalence v ČR – pro odhad těchto tohoto parametrů bylo jen velice málo dat (malé desítky pozorování), proto jsem ji odhadl “expertně” (konkrétně na základě optické shody posledních pozorování a předpovědí) s tím, že jsem vědomě v rámci předběžné opatrnosti zvolil “horší” variantu, což jsem ostatně výslovně v prezentaci uvedl. Nyní, s odstupem čtrnácti dnů, je jasné, že je tento parametr nižší, což bude doufám v budoucnosti znamenat větší než předpokládaný pokles hospitalizací i úmrtí.
Co říci závěrem? Kdyby existoval spolehlivý model vývoje epidemie pro ČR, já ani moji kolegové bychom necítili potřebu (zbytečně) vyvíjet vlastní. Vždy se nabízí otázka, zda ještě nedokonalou verzi modelu aplikovat, nebo “raději mlčet”. Na tuto otázku není jednoduchá odpověď – i my v BISOP jsme několikrát byli v situaci, která byla nejistá do té míry, že jsme se jakékoliv předpovědi raději zdrželi – v tomto kontextu připomínám třeba tento náš článek z podzimu minulého roku. V tomto případě však byla situace taková, že ohledně dalšího vývoje epidemie neexistovala prakticky žádná prognóza. V takovém případě je lepší i přes nejistotu mluvit než mlčet.
Z podstaty věci je zřejmé, že žádný dokonalý model neexistuje, vždy je co kritizovat. Zodpovědný kritik by však podle mého názoru měl také nabídnout nějakou alternativu – příliš často vidím, že onou alternativou jsou pouze osobní názory, často nepodložené skoro žádnými objektivními daty.